[ FEATURED_MODULE.DLL ]v2.0.0
AI Engineering
⋅5 min read
Why I Compiled My Time Series Forecasting Engine to WebAssembly
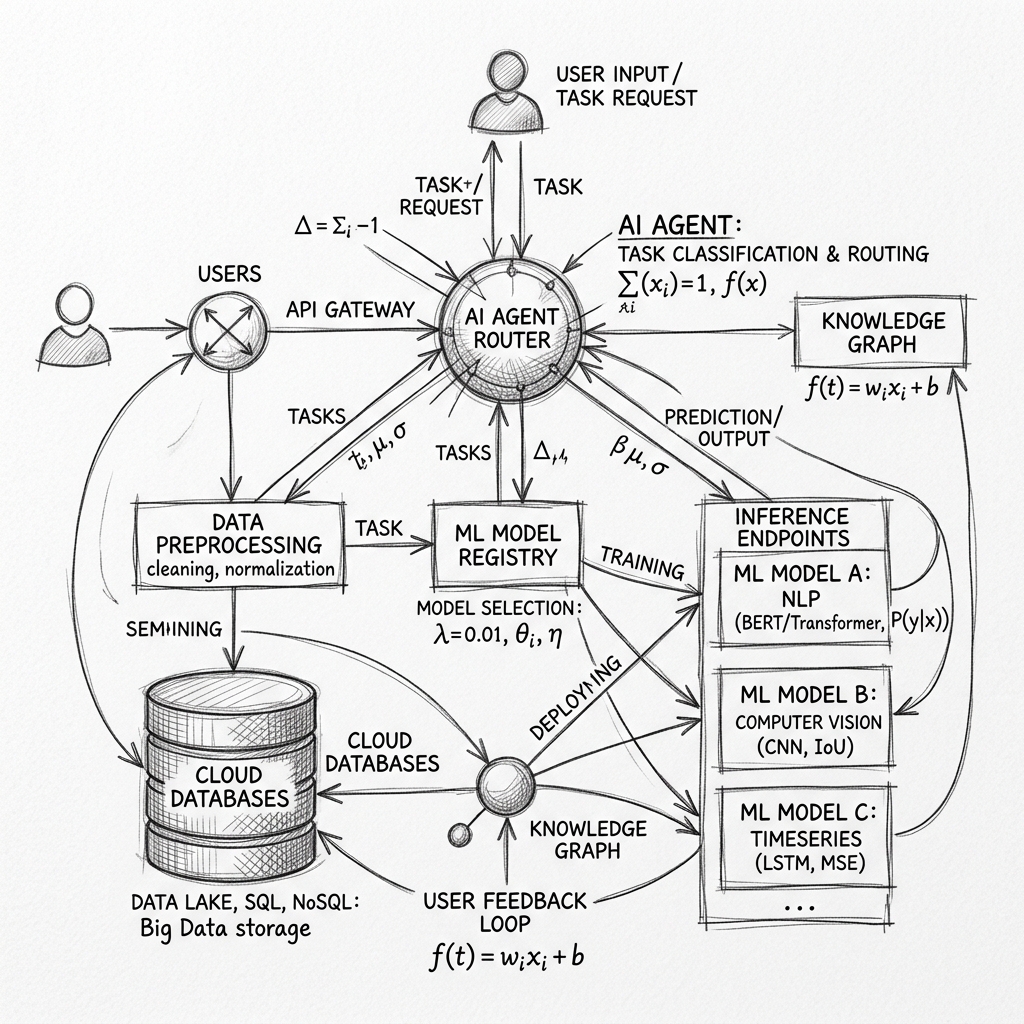
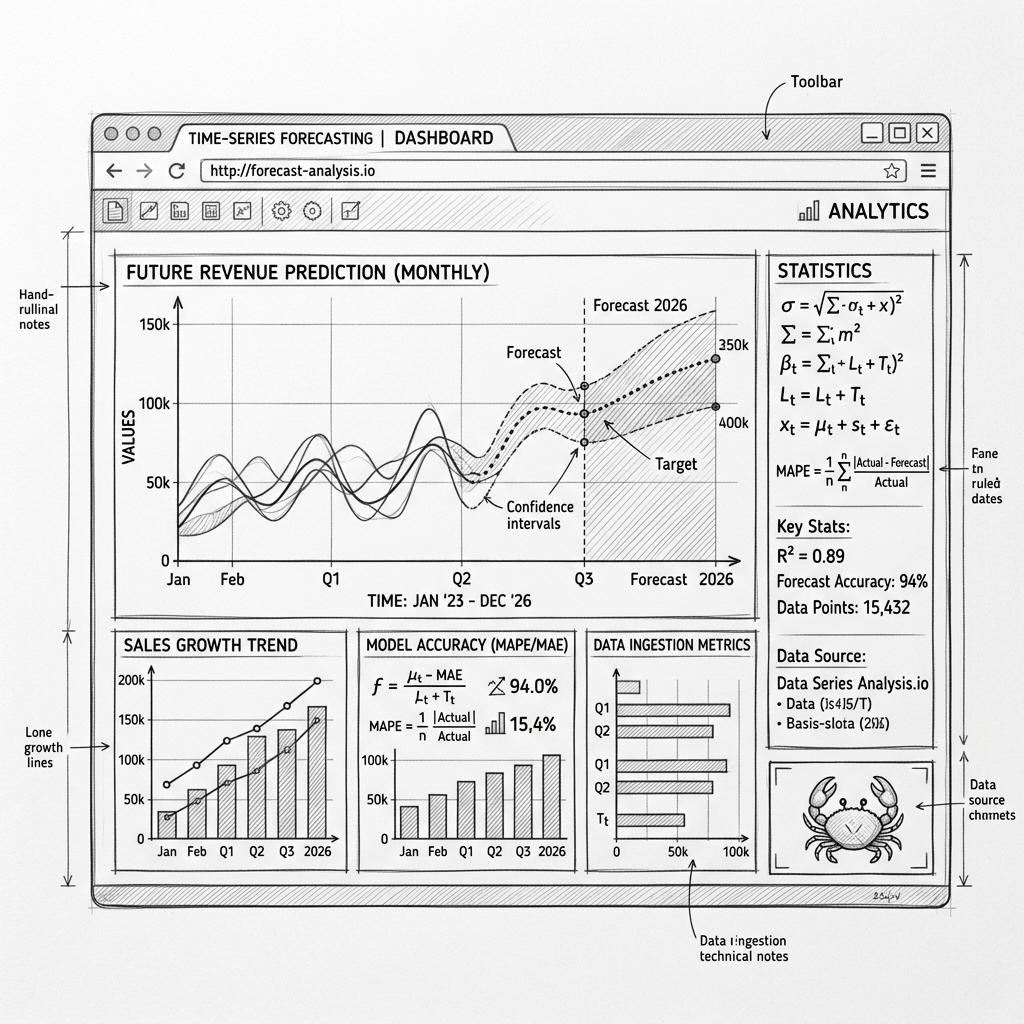
Privacy-first forecasting sounds nice in theory. In practice, running statistical packages like ARIMA and exponential smoothing on raw CSVs at the edge meant compiling Rust to WebAssembly. Here is how I built it.
Dan